음성 인식은 인공지능 분야에서 중요한 주제 중 하나로, 음성을 텍스트로 변환하는 기술입니다. 이 기술은 음성 명령 인식, 자동 번역, 음성 검색 등 다양한 응용 분야에서 사용되고 있습니다.
DeepSpeech의 초기 버전은 2017년에 처음으로 공개되었습니다. 이후 Mozilla는 지속적으로 DeepSpeech를 업데이트하고 개선해왔으며, 커뮤니티의 참여와 기여를 받아 오픈 소스 프로젝트로 발전시켜 왔습니다. 현재는 오래된 코드로 Benchmark로 구성하거나 과거 모델부터 구현하고 공부하기 위한 분들을 위한 환경 세팅을 공유하고자 작성하게 되었습니다.
DeepSpeech는 다양한 데이터셋으로 학습할 수 있으며, 이 중 Kspon 데이터셋은 AI-Hub에서 공개된 한국어 음성 인식에 특화된 데이터셋입니다. DeepSpeech를 사용하여 Kspon 데이터셋을 학습하기 위한 환경 구성에 대해 알아보겠습니다. 우리는 DeepSpeech를 설치하고, Kspon 데이터셋을 사전 처리한 후 모델 학습을 시작할 것입니다. 이제부터 차례대로 DeepSpeech와 Kspon 데이터셋, 그리고 DeepSpeech를 위한 환경 구성에 대해 알아보도록 하겠습니다.
DeepSpeech 소개
paper : https://arxiv.org/abs/1412.5567
github : https://github.com/mozilla/DeepSpeech
DeepSpeech는 Mozilla가 개발한 오픈 소스 음성 인식 엔진으로, 딥러닝 알고리즘을 사용하여 음성 데이터를 텍스트로 변환하는 기술입니다. DeepSpeech는 딥러닝의 한 종류인 장단기 메모리(Long Short-Term Memory, LSTM) 네트워크를 기반으로 합니다.
DeepSpeech의 동작 원리는 크게 세 가지 단계로 나눌 수 있습니다:
1. 음성 데이터의 특성 추출:
DeepSpeech는 입력으로 주어진 음성 데이터를 특성으로 추출하여 사용합니다. 주로 Mel-Frequency Cepstral Coefficients(MFCCs)를 사용하여 음성의 주파수 특성을 표현합니다. 이러한 특성은 음성의 주파수 스펙트럼을 시간에 따른 특징 벡터로 변환합니다.
2. 음성 데이터의 시퀀스 모델링:
추출된 음성 특성은 LSTM 네트워크를 사용하여 시퀀스 모델링을 수행합니다. LSTM은 시간적인 의존성을 모델링할 수 있는 장기 메모리와 현재 입력에 대한 잊어버릴 수 있는 단기 메모리를 갖추고 있는 인공신경망의 한 종류입니다. LSTM은 음성 데이터의 시계열적인 특성을 이해하고, 각 프레임의 특징 벡터를 기반으로 다음에 올 문자를 예측합니다.
3. 텍스트로의 변환:
LSTM 네트워크를 통해 예측된 문자 시퀀스는 텍스트로 변환됩니다. 이 과정에서 텍스트 디코딩 알고리즘을 사용하여 확률적으로 가장 가능성이 높은 텍스트 시퀀스를 결정합니다. 이렇게 변환된 텍스트는 원래 음성 데이터의 텍스트 표현으로 사용될 수 있습니다.
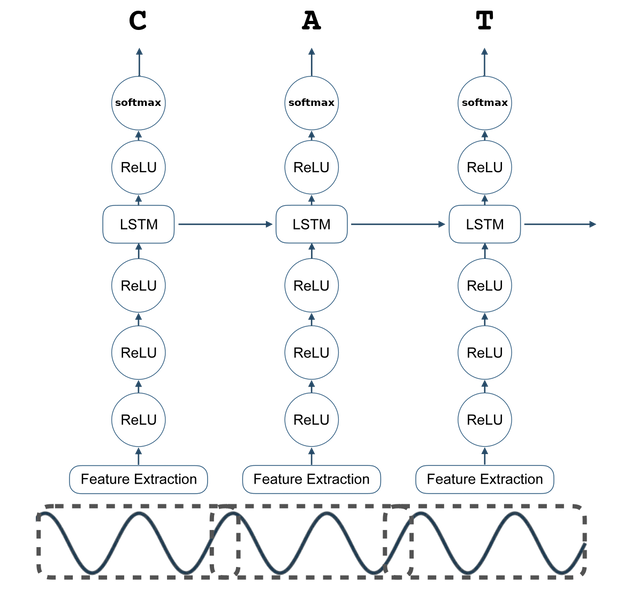
DeepSpeech는 딥러닝 알고리즘을 사용하므로, 학습을 위해서는 대량의 레이블된 음성 데이터가 필요합니다. 이를 통해 DeepSpeech 모델은 음성 데이터의 다양한 특징을 학습하고, 음성에서 텍스트로의 변환을 수행할 수 있게 됩니다.
딥러닝을 기반으로 한 DeepSpeech는 다양한 응용 분야에서 사용될 수 있으며, 오픈 소스로 제공되어 개발자들이 쉽게 활용할 수 있습니다. 또한, DeepSpeech는 확장성과 유연성을 갖추고 있어 다양한 언어와 데이터셋에 대한 학습이 가능합니다.
이제 DeepSpeech의 개념과 동작 원리에 대해 간략하게 소개해보았습니다. 다음으로 Kspon 데이터셋에 대해 알아보고 DeepSpeech를 위한 환경 구성에 대해 다루어보겠습니다.
Kspon 데이터셋
Kspon(Korean Speech Recognition Corpus) 데이터셋은 한국어 음성 인식을 위해 구축된 대규모 음성 데이터셋입니다. 이 데이터셋은 한국어 음성 인식 모델의 학습과 평가를 위해 사용될 수 있습니다. Kspon 데이터셋은 다음과 같은 특징과 구성을 갖추고 있습니다:
대상 언어는 한국어이고 구축 분량은 대화음성 1,000시간에 해당한다. 두 사람이 조용한 환경에서 자유롭게 대화하는 음성을 녹음하고 전사규칙(부록: ETRI 전사규칙)에 따라 음성내용이나 잡음을 소리값에 충실하게 일관성 있게 전사한다. 최종 음성데이터 포맷은 16KHz, 16bits headerless linear PCM, 텍스트는 EUC-KR 코드로 저장한다. 본 DB 구축에 참여한 전체 화자는 총 2,000명 으로 성별 비율은 남 46%, 여 54%로 나누어져 있습니다.
대화의 주제는 예시로 안부 일상대화, 날씨, 쇼핑, TV, 정치, 경제, 취미 등의 특정 주제에 편중되지 않도록 구성이 되어있습니다. 자세한 내용은 AI-Hub에서 한국어 음성 데이터셋을 다운받아 데이터셋 구성 가이드를 확인하면 되겠습니다.
제가 테스트한 환경은 다음과 같습니다.
Develop Environment
Ubuntu : 20.11
Local Python version : 3.6
CUDA 10.0
CUDNN : 7.6
참고) Docker를 사용한 환경 세팅
Dockerfile을 통해 환경을 구축하실 분은 아래와 같은 명령어로 구성하시면 됩니다.
$ docker pull tensorflow/tensorflow:1.15.4-gpu-py3
$ docker run --gpus 1 -it -v [로컬연결디렉토리]:/[docker에서연결위치] tensorflow/tensorflow:1.15.4-gpu-py3Training을 위한 Dockerfile은 github repository에서 다운받은 후 Dockerfile.train을 통해 세팅하시면 됩니다.
$ git clone https://github.com/mozilla/DeepSpeech.git
$ make Dockerfile.train다른 DeepSpeech 리포지토리/브랜치를 지정하려면 다음을 전달할 수 있습니다.
DEEPSPEECH_REPO or DEEPSPEECH_SHA parameters:
$ make Dockerfile.train DEEPSPEECH_REPO=git://your/fork DEEPSPEECH_SHA=origin/your-branch
Ubuntu Local Python상에서의 환경 세팅
python3.6의 venv 가상환경 생성
$ python3 -m venv deepspeech
$ source deepspeech/bin/activate
python 3.6상에서 가상환경 활성화가 완료되면 관련 dependency 라이브러리를 설치해 줍니다.
(deepspeech)$ git clone https://github.com/mozilla/DeepSpeech.git
(deepspeech)$ cd DeepSpeech
(deepspeech)$ pip3 install --upgrade pip==20.2.2 wheel==0.34.2 setuptools==49.6.0
(deepspeech)$ pip3 install --upgrade -e .webrtcvad Python 패키지는 Python 모듈을 빌드하기 위한 적절한 도구가 있는지 확인하도록 요구할 수 있습니다.
(deepspeech)$ sudo apt-get install python3-dev
Training을 GPU상에서 해주기 위해 Tensorflow 1.xx 버전은 tensorflow-gpu 버전을 설치해 주어야합니다.
(deepspeech)$ pip uninstall tensorflow
(deepspeech)$ pip install 'tensorflow-gpu==1.15.4'
Kspon Dataset
AI-Hub 사이트에 접속하여 [한국어 음성] 데이터를 검색한 후 다운로드 받으면 아래와 같이 폴더가 존재합니다.
한국어 음성
├ 전시문_통합_스크립트
├ 평가용_데이터
└ 한국어_음성_분야학습용 데이터는 /KsponSpeech 폴더 안에 1개 문장에 해당하는 pcm 음성파일과 txt 전사문으로 구성됩니다.
예) /KsponSpeech_0001/KsponSpeech_000001.pcm, KsponSpeech_000001.txt
전사문 통합스크립트는 개발자가 언어모델이나 텍스트 처리 편의를 위해 각 폴더안에 있는 전사문을 통합한 파일입니다.
평가용 데이터는 학습용 데이터에 사용되지 않은 데이터로 난이도에 따라 Eval_clean (2.6시간), Eval_other(3.8시간)로 나누고, 화자적응용 Train_adapt(25.7시간) 등 크게 3가지로 구성됩니다.
Deepspeech에서 쓰이는 Deepspeech Doc. 에 있는 내용으로는 Training set으로 Common Voice training dataset을 전처리 과정을 통해 Clips폴더 안에 예를 들자면 speech_00001.wav 등의 오디오 파일이 존재하고 Label로 train.csv, dev.csv, test.csv로 구성되어있고 .csv안에는 filename과transcripts로 구성되어있습니다.
Clips
├ Kspoonspeech_000001.wav
├ .....
├ Kspoonspeech_099999.wav
├ train.csv
├ dev.csv
└ test.csv
이와 같은 형식으로 Kspon Dataset도 맞추기 위해 같은 형식으로 전처리 작업을 진행해야합니다.
또 한 Kspoon 데이터의 전사 규칙등으로 인해 특수기호, 부호 등도 깔끔하게 Training이 가능하도록 처리해 주어야 합니다.
Kspoon Dataset의 전처리 코드 중에 가장 많이 쓰이는 github 주소를 보고 참고하여 수행하면 됩니다.
Kspoon dataset preprocessing source : https://github.com/sooftware/ksponspeech
GitHub - sooftware/ksponspeech: Pre-processing KsponSpeech corpus (Korean Speech dataset) provided by AI Hub.
Pre-processing KsponSpeech corpus (Korean Speech dataset) provided by AI Hub. - GitHub - sooftware/ksponspeech: Pre-processing KsponSpeech corpus (Korean Speech dataset) provided by AI Hub.
github.com
또한 Kspoon data의 원본 오디오 파일은 .pcm 파일이므로 학습엔 .wav 파일이 쓰여 이를 변환하는 코드는 다음과 같습니다.
import os
from tqdm import tqdm
import struct
import pathlib
# pcm_clips 폴더 경로
pcm_clips_dir = "/home/work/speech/data/evaluation_data/eval_clean"
# pcm_clips_dir = "/home/work/speech/data/evaluation_data/eval_other"
output_dir = "./wav_eval_clean"
def make_wav_format(pcm_data:bytes, ch:int) -> bytes:
"""
pcm_data를 통해서 wav 헤더를 만들고 wav 형식으로 저장한다.
:param pcm_data: pcm bytes
:param ch: 채널 수
:return wav: wave bytes
"""
waves = []
waves.append(struct.pack('<4s', b'RIFF'))
waves.append(struct.pack('I', 1))
waves.append(struct.pack('4s', b'WAVE'))
waves.append(struct.pack('4s', b'fmt '))
waves.append(struct.pack('I', 16))
# audio_format, channel_cnt, sample_rate, bytes_rate(sr*blockalign:초당 바이츠수), block_align, bps
if ch == 2:
waves.append(struct.pack('HHIIHH', 1, 2, 16000, 64000, 4, 16))
else:
waves.append(struct.pack('HHIIHH', 1, 1, 16000, 32000, 2, 16))
waves.append(struct.pack('<4s', b'data'))
waves.append(struct.pack('I', len(pcm_data)))
waves.append(pcm_data)
waves[1] = struct.pack('I', sum(len(w) for w in waves[2:]))
return b''.join(waves)
# pcm_clips 폴더 내의 모든 .pcm 파일 순회
for pcm_file_name in tqdm(os.listdir(pcm_clips_dir)):
if pcm_file_name.endswith(".pcm"):
pcm_file_path = os.path.join(pcm_clips_dir, pcm_file_name)
pcm_bytes = pathlib.Path(f"{pcm_file_path}").read_bytes()
wav_bytes = make_wav_format(pcm_bytes, 1)
path222 = os.path.splitext(pcm_file_name)[0]
with open(f'{os.path.join(output_dir,os.path.splitext(pcm_file_name)[0])}.wav', 'wb') as file:
file.write(wav_bytes)
import csv
# Define the file paths for train.csv, test.csv, and dev.csv
train_csv_path = "train.csv"
test_csv_path = "test.csv"
dev_csv_path = "dev.csv"
# Set to store unique characters from the transcripts
vocab = set()
# Function to extract characters from a given text and add them to the vocabulary
def process_text(text):
for char in text:
vocab.add(char)
# Read train.csv
with open(train_csv_path, "r", encoding="utf-8") as train_file:
reader = csv.DictReader(train_file)
for row in reader:
process_text(row["transcript"])
# Read test.csv
with open(test_csv_path, "r", encoding="utf-8") as test_file:
reader = csv.DictReader(test_file)
for row in reader:
process_text(row["transcript"])
# Read dev.csv
with open(dev_csv_path, "r", encoding="utf-8") as dev_file:
reader = csv.DictReader(dev_file)
for row in reader:
process_text(row["transcript"])
# Save the vocabulary to ai_hub_spelling_vocab.txt
with open("ai_hub_spelling_vocab.txt", "w", encoding="utf-8") as vocab_file:
for char in sorted(vocab):
vocab_file.write(char + "\n")
Training
$ python DeepSpeech.py --train_files data/Kspon/clips/train.csv \
--dev_files data/Kspon/clips/dev.csv \
--test_files data/Kspon/clips/test.csv \
--alphabet_config_path data/Kspon/ai_hub_spelling_vocab.txt \
--checkpoint_dir ./checkpoints/Kspon/checkpoints \
--summary_dir ./checkpoints/Kspon/summary \
-- test_output_file ./checkpoints/Kspon/test_output \
--save_checkpoint_dir ./checkpoints/Kspon/save_checkpoints
$ horovodrun -np 2 -H localhost:2 python DeepSpeech.py \
--train_files data/0531_Kspon/clips/train.csv \
--dev_files data/0531_Kspon/clips/dev.csv \
--test_files data/0531_Kspon/clips/test.csv \
--alphabet_config_path data/Kspon/ai_hub_spelling_vocab.txt \
--checkpoint_dir ./checkpoints/Kspon/checkpoints \
--summary_dir ./checkpoints/Kspon/summary \
--test_output_file ./checkpoints/Kspon/test_output \
--save_checkpoint_dir ./checkpoints/Kspon/save_checkpoints \
--horovod
export
$ python DeepSpeech.py --export_dir export_folder/ \
--load_checkpoint_dir Training_완료된_checkpoints_DIR/
scorer
$ python3 data/lm/generate_lm.py --input_txt merge_news_corpus.txt.gz \
--output_dir . --top_k 500000 \
--kenlm_bins /home/work/speech/project/DeepSpeech/kenlm/kenlm/build/bin \
--arpa_order 5 --max_arpa_memory "85%" \
--arpa_prune "0|0|1" \
--binary_a_bits 255 \
--binary_q_bits 8 \
--binary_type trie
$ ./native_client/generate_scorer_package --alphabet data/Kspon/ai_hub_spelling_vocab.txt \
--lm data/lm.binary \
--vocab data/vocab-500000.txt \
--package ./Kspon_news_corpus_output.scorer \
--default_alpha 0.931289039105002 \
--default_beta 1.1834137581510284
pbmm
$ /절대경로/convert_graphdef_memmapped_format --in_graph=export_folder/output_graph.pb \
--out_graph=kspon_output_graph.pbmm
'Artificial Intelligence > Speech Recognition' 카테고리의 다른 글
| Insanely Fast Whisper 리뷰 (0) | 2024.06.05 |
|---|---|
| OpenAI - Whisper JAX 수행하기 위한 Anaconda 환경 구성 및 테스트 (2) | 2023.06.01 |

